Siła PHP w połączeniu z bazą danych RDBMS polega na możliwości tworzenia głównych elementów aplikacji niedużym kosztem i w krótkim czasie. Niestety domyślne środowisko uruchomieniowe PHP nie jest skalowalne, przez co w przypadku bardziej skomplikowanych aplikacji po prostu niewystarczające. Chmura oraz wykorzystanie baz danych NoSQL mogą w tym zakresie znacznie zwiększyć możliwości tej popularnej platformy programistycznej.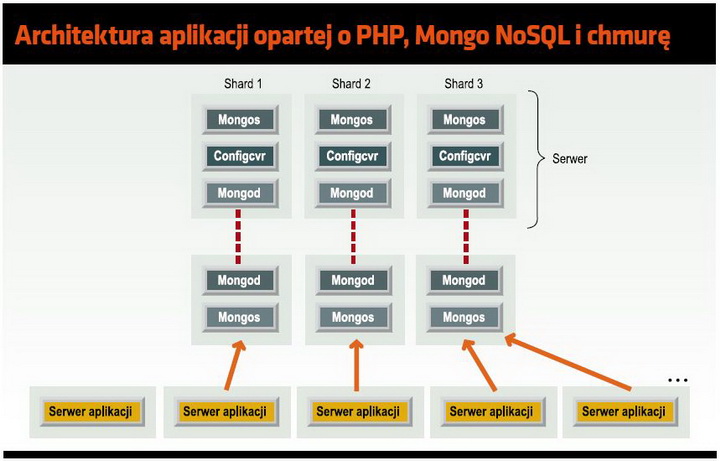
Wielu programistów nie przejmuje się utrzymaniem i hostingiem tworzonych przez siebie aplikacji PHP. Ich aplikacje sprawiają wrażenie jednorazowych, a przy tym bardzo często są mocno obciążane przez wielu użytkowników. Weźmy dla przykładu aplikację PHP z relacyjną bazą Oracle dla firmy marketingowej, która umożliwia zakup produktów i wymianę uzyskanych punktów na dodatki do gry online. Sprawdza się ona doskonale, do czasu gdy zacznie z niej korzystać kilka milionów użytkowników.
Teoretycznie, jeśli dysponujemy wystarczającą liczbą serwerów, nie powinno być problemów. Jednak kombinacja PHP z relacyjną bazą danych jest trudna do efektywnego skalowania, tak aby osiągnąć jednocześnie odpowiednią wydajność odczytu i zapisu danych.
Jednym z możliwych rozwiązań w tej sytuacji jest zastosowanie hostingu w chmurze oraz baz NoSQL (Not only SQL). Infrastruktura cloud pozwala na elastyczne rezerwowanie zasobów i uruchamianie kolejnych serwerów, natomiast bazy NoSQL pozwalają bardziej efektywnie czerpać dane.
Typowo i niewydajnie
Zastanówmy się najpierw, zanim opiszemy zalety nowego podejścia, czemu typowe środowisko uruchomieniowe PHP jest nieoptymalne
Najpopularniejsza instalacja, w której pracuje PHP to webserwer Apache z modułem PHP w trybie prefork. Ten tryb oznacza, że serwer webowy uruchamia serię osobnych podprocesów, aby obsłużyć konkurencyjne żądania. Kiedy połączymy tę konkurencyjną specyfikę z tradycyjną bazą danych, jak np. MySQL, PostgreSQL czy Oracle, to rozwiązanie spowoduje rozłączne połączenia z bazą danych - ich łączenie (pooling) wymaga współdzielonego obszaru pamięci.
Z drugiej strony natywne wątki mają współdzielone obszary pamięci jako część procesu głównego. Podprocesy nie mają współdzielonego obszaru pamięci, chyba że używamy specyficznego obszaru systemu - pamięci współdzielonej. To rozwiązanie nie jest jednak tak szybkie jak przekazywanie pamięci przez referencje, poza tym Apache w trybie prefork nie pozwala na stosowanie współdzielonej pamięci w tym celu. Możliwe jest uruchomienie PHP w natywnych wątkach w trybie worker, ale ograniczeniem może być lista modułów dostępnych w tym trybie i to, czy są one "wątkowo bezpieczne".
Model konkurencyjny w PHP ma główny wpływ na pionową skalowalność, gdy korzystamy z tradycyjnych baz RDBMS. Podczas gdy jest możliwe otwarcie tysięcy niewspółdzielonych, jednoczesnych połączeń do MySQL czy Oracle, ma to negatywny wpływ na liczbę jednoczesnych żądań. Typowa aplikacja internetowa działa według następującej logiki:
żądanie - pobranie danych - wykonanie operacji - pobranie większej ilości danych - wykonanie dodatkowych operacji - zapisanie danych - wysłanie odpowiedzi
W tego rodzaju kodzie występują dość długie okresy, w których aplikacja nie wymienia danych z bazą danych i inne żądanie mogłoby "skorzystać" z tego samego połączenia z bazą danych. Oczywiście, gdyby możliwy był pooling połączeń. Ponieważ model procesów PHP to uniemożliwia, jesteśmy zmuszeni do podjęcia decyzji: albo utrzymać połączenie na czas cyklu żądania/odpowiedzi, albo tworzyć je za każdym razem.
Problem z każdorazowym uruchamianiem połączenia polega na tym, że zależy od charakterystyki wydajności otwierania połączeń socket. Stos TCP jest skonfigurowany do ochrony przed "osieroconymi" pakietami z poprzedniego połączenia, przerywającymi nowe połączenie. To część zabezpieczeń spójności, które TCP dodaje do IP. TCP/IP zapewnia tę funkcjonalność poprzez wprowadzanie opóźnienia, w celu ponownego użycia tego samego połączenia socket. Dlatego liczba połączeń TCP socket możliwych do otwarcia w ciągu sekundy jest limitowana. Jednym ze sposobów na ominięcie tego ograniczenia jest ponowne wykorzystanie połączeń między wieloma cyklami żądań. Niestety, ze względu na wspomniany model konkurencyjny PHP nie jest łatwo skorzystać z tego.
Jeśli wyświetlimy listę aktywnych połączeń w serwerze webowym albo bazodanowym podczas działania aplikacji PHP (wykonując polecenie netstat -na), zobaczymy dużą liczbę połączeń do lub z bazy danych w stanach TIME_WAIT albo CLOSE_WAIT. Gdybyśmy uruchomili tę aplikację w środowisku, które pozwala na "pulowanie" połączeń, zobaczylibyśmy stałą liczbę (równą skonfigurowanemu rozmiarowi puli) w stanie ESTABLISHED.
Dlaczego PHP pracuje w ten sposób? Początkowo Linux nie obsługiwał wątków a tylko podprocesy. Systemy wywodzące się z Windows NT od zawsze wspierały wątki (chociaż "cięższe" od tych z nowszych wersji Linuksa) i mogło to stanowić ich dużą przewagę. Microsoft nie potrafił jednak tego przekonująco dowieść.
Aby skalować aplikację PHP opartą na relacyjnej bazie danych, warto podzielić na kawałki dane. Oczywiście, należy zrobić to w sposób racjonalny - dla przykładu można podzielić klientów aplikacji na regiony (np. województwa).
Chmura i NoSQL wchodzą do gry
W chmurze nie ma obaw o wydajność konwencjonalnej aplikacji opartej nawet na bazie relacyjnej, kiedy zapewnione jest odpowiednie balansowanie obciążenia. Zamiast serii niepulowanych połączeń do jednej lub 2 maszyn, można rozkładać obciążenie na dużo więcej serwerów bazodanowych.
Większa liczba serwerów webowych ogranicza wpływ braku mechanizmu pulowania połączeń dla klientów bazy danych. Większa liczba baz danych i ich dzielenie na kawałki ograniczają wpływ tego problemu na serwery. Przejście na NoSQL i chmurę może znacznie podnieść skalowalność nawet w obecnych środowiskach uruchomieniowych. Czynniki ekonomiczne, które spowodowały tak dużą popularność PHP, dzięki takiemu podejściu nie tracą na swojej sile.
Jednoczesna migracja do chmury i do przechowywania danych w bazach NoSQL eliminują wspomniane problemy ze skalowalnością. Rozwiązań i produktów pozwalających na uruchomienie aplikacji PHP w środowisku cloud jest dostępnych już wiele. W przypadku baz NoSQL oferowanych jest już kilka projektów, ale trzeba będzie trochę poczekać na "zaprzyjaźnienie" się z nimi większego grona specjalistów i analityków, którzy do tej pory wybierali sprawdzone przez lata tradycyjne silniki relacyjnych baz danych (jednym z przykładów baz danych NoSQL o otwartym kodzie jest Mongo).


 Ukryj panel
Ukryj panel






![[RSS]](images/rss_bigs.png "Kliknij i subskrybuj RSS-a")
